¿Qué son los embeddings?
Antes de entrar en el diseño del módulo conviene fijar el concepto sobre el que se construye todo el capítulo.
Un embedding es la representación numérica de un concepto en un espacio de alta dimensión, de tal forma que los conceptos semánticamente similares quedan geométricamente próximos. En lugar de manejar una palabra como una cadena de caracteres —opaca para cualquier cálculo matemático—, un modelo de embeddings la transforma en un vector de cientos o miles de números reales que codifica su significado.
Para verlo en la práctica, consideremos tres palabras: King, Man y Woman. Un modelo entrenado sitúa cada una en un punto distinto del espacio vectorial:
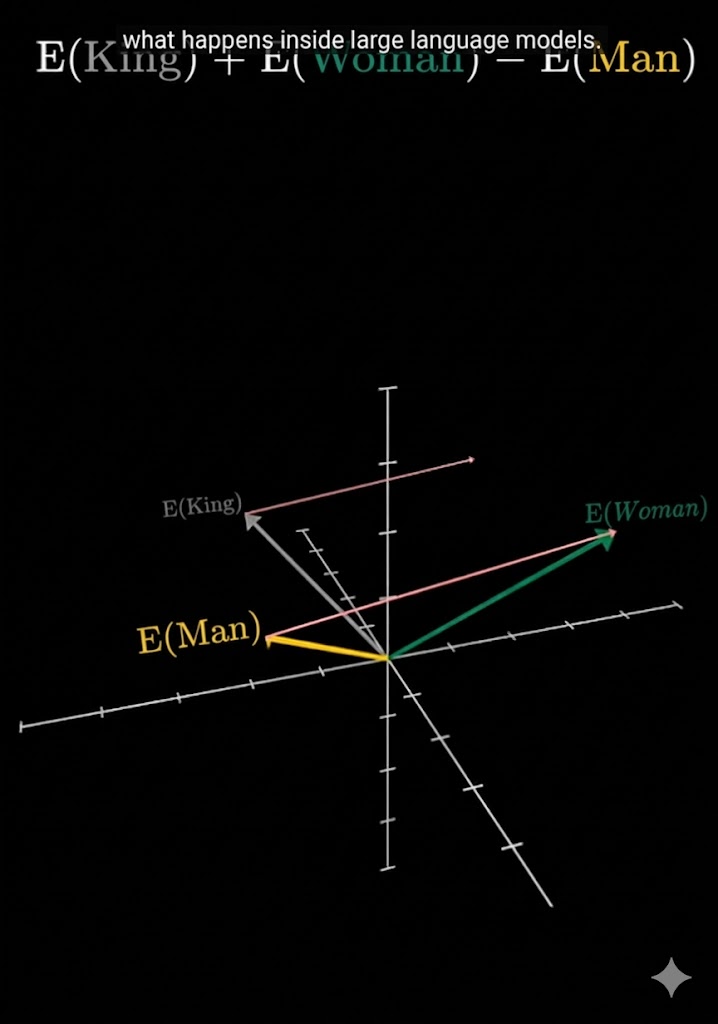
Lo interesante no es la posición individual, sino la estructura del espacio: las distancias y direcciones entre vectores codifican relaciones de significado. Esto permite operar con ellos como si fueran números y obtener resultados con sentido lingüístico — la llamada aritmética semántica. Si al vector de King le sumamos el de Woman y le restamos el de Man, estamos preguntando matemáticamente: "¿qué es a la mujer lo que el rey es al hombre?"
E(King) + E(Woman) − E(Man) ≈ E(Queen)
El vector resultante no corresponde a ninguna de las palabras de partida, pero el punto más cercano del espacio es, precisamente, Queen:
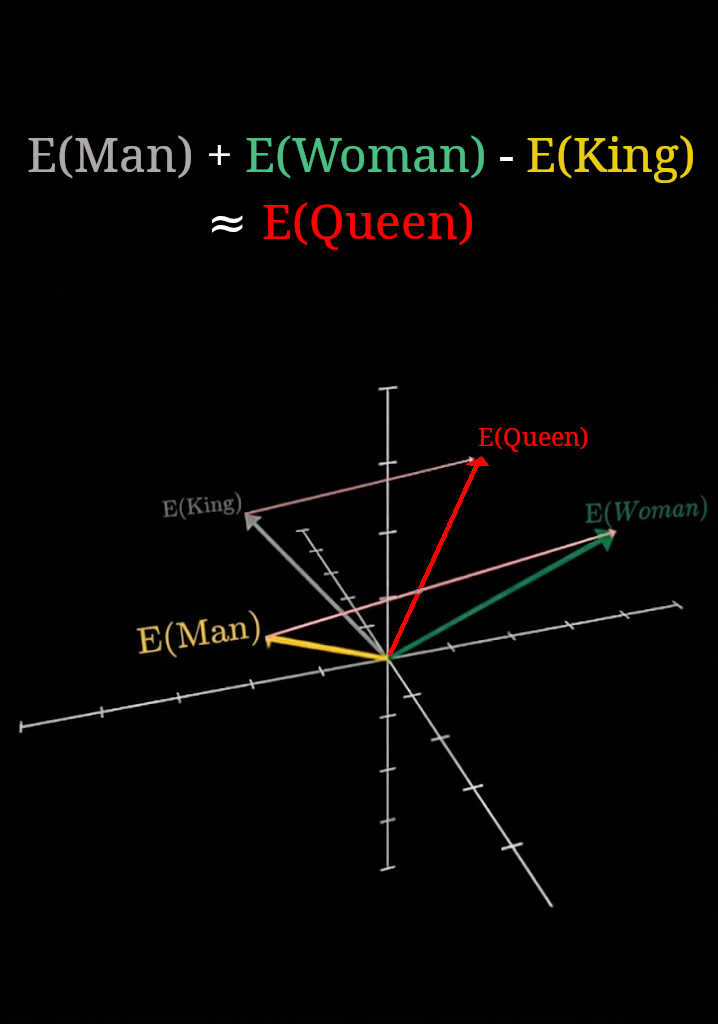
No es un truco: refleja que el modelo ha aprendido que la diferencia entre rey y hombre —la dimensión de la realeza— es la misma que la diferencia entre reina y mujer, y esa simetría queda codificada en la geometría del espacio.
Del concepto al sistema real
La intuición anterior funciona con un espacio reducido a tres palabras, pero un modelo industrial trabaja con dimensiones mucho más altas. En este TFG el modelo utilizado es gemini-embedding-001, que produce vectores de 768 dimensiones: cada recurso de DWall — una variable, una regla, una consulta — termina representado por una lista de 768 números reales. Cada dimensión captura una característica abstracta del significado del texto que el modelo aprendió durante su entrenamiento; el conjunto de las 768 es lo que le da capacidad de discriminar entre conceptos parecidos.
La búsqueda semántica: encontrar por significado
Una vez los recursos están proyectados al espacio vectorial, la pregunta natural es cómo se aprovecha esa proyección. La respuesta es la búsqueda semántica: en lugar de buscar coincidencias literales de texto, el sistema convierte la consulta del usuario al mismo espacio vectorial y devuelve los recursos cuyos vectores se encuentran geométricamente más cerca de ella.
A diferencia de la búsqueda léxica clásica — la del LIKE %temperatura% que cualquier base de datos relacional ofrece —, la búsqueda semántica mira el significado y no los caracteres. Eso resuelve tres problemas que en un entorno industrial son cotidianos:
- Sinónimos y terminología técnica. Una consulta por "rendimiento" puede recuperar recursos descritos como "performance" o "efficiency", sin que el usuario tenga que conocer la palabra exacta usada por quien dio de alta el recurso.
- Multilingüismo. Los modelos de embeddings de Gemini son multilingües por construcción. Una pregunta en euskera puede recuperar correctamente una variable descrita en castellano, lo que importa cuando el cliente trabaja en plantas con equipos internacionales.
- Tolerancia a errores. Pequeñas erratas o variaciones gramaticales no descarrilan la búsqueda como sí lo harían los filtros tipo
LIKE. "compresor de aire" y "compresor d'aire" viven cerca en el espacio vectorial y se recuperan juntos.
En una plataforma como DWall, donde los recursos suelen tener nombres opacos como IGE12_T_OUT o WTG_RPM_AVG, esto significa que un operador puede preguntar por "temperatura de salida del aceite" y obtener la variable correcta sin conocer su código técnico.
Lo que esto habilita en DWall
Con estas dos piezas — el vector como representación del significado y la búsqueda por proximidad en el espacio — el sistema deja de buscar coincidencias de texto y pasa a buscar coincidencias de significado. Eso es lo que abre la puerta a dos usos complementarios dentro de la plataforma: el filtro semántico en el explorador de variables, accesible para cualquier operador desde la interfaz sin necesidad de pasar por el chatbot, y el agente RAG, que utiliza la misma infraestructura para recuperar el contexto que necesita antes de responder a una pregunta compleja.
El resto del capítulo asume estas dos piezas como dadas y se centra en lo que sí es decisión de diseño: dónde se almacenan los vectores, cómo se generan, cuándo se regeneran y cómo se exponen al resto del sistema.